Where can I learn about how DALYs are calculated?
By Aaron Gertler 🔸 @ 2022-06-10T22:03 (+45)
I recently tried to figure out where DALYs come from.
After a bit of searching, the best I could find was this report on the origin of the metric (the first Global Burden of Disease assessment). The report includes this explanation:

And:

But I'm left with many other questions:
- How many health workers were consulted?
- Were people other than health workers consulted, especially people who have themselves experienced the relevant health issues?
- Were DALY values updated in successive instances of the GBD?
- Are transcripts of any of these "formal exercises" available somewhere?
Ideally, I'd love to find a document/video that covers DALYs in the style of a factory tour video; I want to know what goes into them, who is involved, and what the creation process looks like.
Does anyone know of such a resource, and/or the answers to any of my questions?
Derek @ 2022-06-12T09:52 (+11)
Some/all answers are in here, or in papers linked in that post. https://forum.effectivealtruism.org/posts/Lncdn3tXi2aRt56k5/health-and-happiness-research-topics-part-1-background-on
Aaron Gertler @ 2022-06-12T20:23 (+9)
This is excellent, thanks!
These two papers, in particular, were what I was looking for. The corresponding information on QALYs was also great.
(For future readers of my post, the relevant info is under the "descriptive system" and "valuation methods" subheadings in Derek's post.)
Amber Dawn @ 2023-02-06T17:34 (+2)
I just had the exact same question, so thanks Aaron for asking this, and Derek for giving this answer :)
brb243 @ 2022-06-10T23:00 (+6)
You can check out the methodology of calculating the most recent dataset (2019). It seems quite legitimate: internationally shared data, Bayesian modeling, compliance with the Guidelines for Accurate and Transparent Health Estimates Reporting (GATHER), etc.
I wonder if any methods/assumptions/biases were carried over from the earlier study that you share. The main bias can be of omission, since health can be a relatively insignificant influence of one's wellbeing. For example, I found (Categorized tab, q4) that only 1/30 slum residents wanted Health to change the most but 8/28 wanted to live 0 additional years (q16). So, people can be healthy (have high QALY) but suffer (low WALY). The dataset can be accurate.
This focus bias can be due to the priority perceptions of the researchers in 1996 (who may have valued health, perhaps since subjective wellbeing improvements were not as readily possible?) in combination with the experimenter bias of the context experts (e. g. due to authority dynamics in these contexts).
Aaron Gertler @ 2022-06-11T01:25 (+5)
Thanks for the link! I was aware of the most recent study, but you prompted me to dig deep and see what they said about their survey methodology.
The most relevant bits I found were sections 4.8 and 4.8.1 in this PDF, which describe multiple surveys done across a bunch of countries.
I'm still not sure where to find actual response counts by country or demographic data on respondents — it's easy to find tons of data on how different health issues are ranked and how common they are, but not to find a full "factory tour" of how the estimates were put together. I'd still be interested in more data on those points (I have to imagine it's buried somewhere in those 1800 pages).
lukeprog @ 2022-06-11T15:22 (+5)
+1 to the question, I tried to figure this out a couple years ago and all the footnotes and citations kept bottoming out without much information having been provided.
brb243 @ 2022-06-11T15:31 (+2)
Yes, for the YLL estimates they combined different datasets to find accurate causes of death disaggregated by age, sex, location, and year. There should be little bias since data is objective and 'cleaned' using relevant expert knowledge. The authors
- Used vital registration (VR)[1] data and combined them with other sources if these were incomplete (2.2.1, p. 22 the PDF)[2]
- Disaggregated the data by "age, sex, location, year GBD cause" (p. 32 the PDF) and made various adjustments for mis-diagnoses and mis-classifications, noise, non-representative data, shocks, and distributed the cause of death data where it made most sense to them, using different complex modeling methods (Section 2 the PDF)
- Calculated YLL by summing the products of "estimated deaths by the standard life
expectancy at age of death"[3]
For YLD estimates, where subjectivity can have larger influence on the results, the authors also compiled and cleaned data, then estimated incidence[4] and prevalence, [5] they severity, using disability weights (DWs) (Section 4 intro, p. 435 the PDF)
- Used hospital visit data (disaggregated by "location, age group, year, and sex" (p. 438) to get incidence and prevalence of diseases/disabilities. Comorbidity correction used a US dataset.
- 140 non-fatal causes were modeled (of which 11 (79–89) relate to mental health diagnoses) (pp. 478–482)
- For each of the causes for a few different severity levels, sequelae were specified.[6]
- Disability weights were taken from a database (GBD 2019) and matched with the sequelae.
- [Section 4.8.1]"For GBD 2010[7] [disability weights] focused on measuring health loss rather than welfare loss" (p. 472). Data was collected in 5 countries (the study samples are claimed to be representative[8]), through in-person computer-assisted interviews and an online survey (advertised in the researchers' networks) (p. 472).
- The in-person survey participants were asked a series of questions about which of two persons (with lay descriptions of sequelae from a random database) is healthier (p. 473)
- The introduction to the questions focused on the relative ability to perform activities[9] (p. 473)
- The online survey participants were asked questions that also compared two health states, but of two differently-sized groups rather than two individuals (p. 473)
- GBD 2013 was conducted online in four European countries (representative age, sex, and education level samples were invited). The survey estimated additional DWs not covered by the 2010 one and re-estimated 30 causes with improved lay descriptions (p. 474)
- Regressions were used to convert the set of preferences between (each of two) health states to 0–1 DW values[10] (p. 474). Comorbidity was corrected for using US data (p. 475)
- GBD 2019 relied on the earlier DWs but used current cause incidence and prevalence (p. 476)
DALY = YLL+YLD (p. 1431)
The GATHER checklist (pp. 1447–1449) includes methodology transparency, stating known assumptions, sharing data (in easily understandable formats), and discussing limitations.
In short, for each of the listed causes, researchers added the years lost and a relatively arbitrary disability burden value to gain the DALY burden. The data does not report wellbeing, does not include health-unrelated situations, and focuses on an objective assessment of respondents' relative abilities to perform tasks rather than subjective perceptions. The ratios of disability weights should be accurate but their valuation relative to death is arbitrary. Thus, it can be that the data is missing the priorities of populations entirely.
I tried figuring out how an adjusted life-year method can be used to estimate population priorities more accurately, and came up (by a series of conversations with EAs and an enumerator in a Kenyan slum and 3 trial surveys) with soliciting sincerity and using the Visual Analog Scale method (the time trade-off and standard gamble methods (source) were rejected since people had difficulties with the math).
- ^
"vital registration (VR) mortality data — anonymized individual-level records from all deaths reported in each country’s VR system occurring between the years of study" (unrelated IHME citation for definition). Page 1445 of the PDF includes a map of data quality (correlates with GDP/capita).
- ^
Also specified in (GBD Compare FAQ): "an adjustment acknowledging that the VR data are biased compared to other sources of data" However, for "non-VR sources, ... data quality can [also] vary widely" (p. 45 the PDF).
- ^
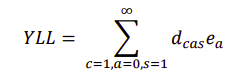
c should be cause, a age, s sex, d number of deaths, e life expectancy (p. 56 the PDF) Even though life expectancy increases with age (England and Wales data example - see maybe 1918), the rate of life expectancy increase should be lower than that of age increase, since YLL "highlights premature deaths by applying a larger weight to deaths that occur in younger age groups" (p. 56 the PDF).
- ^
Incidence: number of new cases or rate of new cases occurrence (IHME terms)
- ^
Prevalence: number of total cases that occurred so far (IHME terms)
- ^
For example, for HIV/AIDS (severity: Symptomatic HIV), the sequelae are "Has weight loss, fatigue, and frequent infections" (p. 485)
- ^
"DWs used in GBD studies before GBD 2010 have been criticized for the method used (ie, person tradeoff), the small elite panel of international public health experts who determined the weights, and the lack of consistency over time as the GBD cause list expanded and additional DWs from a study in the Netherlands were added or others were derived by ad-hoc methods" (p. 472). So, the 1996 source that you cite may be biased.
- ^
The design implies that computers were accessible in the study locations. In my small-scale survey in a Kenyan slum, the local enumerator refused to take a smartphone to collect data (instead used paper) due to security concerns. (Also, enumeration by a computer can motivate experimenter bias 'how they would be judged by (a traditional) authority' rather than responses based on inner thoughts' and feelings' examination.) Further, non-response attrition rate was not specified but "as many as three return visits [or up to seven calls] were made to do the survey at a time when the respondent was available" (p. 472). If attrition is relatively high, selection bias can occur. So, the sample may be not representative and data biased.
- ^
“A person’s health may limit how well parts of his body or mind work. As a result, some people are not able to do all of the things in life that others may do, and some people are more severely limited than others" (p. 473). This can further bias people to give objective answers on the extent to which their activities compare to that of others rather than focus on their subjective perceptions or share what they think about health.
- ^
A probit regression that estimated if the health state was the first (value: 1) or second (value: -1) (I imagine that the probit curve would lie between y=-1 and y=1) in a pair was used to get the relative distances among the health states (p. 474). The probit coefficient associated with each cause were linearly regressed onto the logit transformed intervals and then numerical integration was used to get the 0–1 DW values (p. 474). Since no logs of either the dependent or independent variables were used, the calculation was not skewed by converting to percentages. It is possible that the range of DW spread (where the relative distances should be accurate) is 'stretched' arbitrarily across the 0–1 range, since no comparisons with death (DW=1) were used. Maybe, all of the DWs should be actually multiplied by 0.1, 10, 0.001?
Jeff Kaufman @ 2022-06-11T21:57 (+4)
Here are some notes from when I looked into this a few years ago: https://www.jefftk.com/p/disability-weights
Aaron Gertler @ 2022-06-12T20:06 (+2)
Thanks! The correlation graphs were helpful to see, though I'm sad about the muddled results from the graph in the updated section.